TIL:Google 搜尋階段、robot.txt、meta robot tag、X-Robots-Tag、標準網址
Disclamer:內容來源為 Gemini 2.5Pro,不保證正確。

Disclaimer:內容來源為 Gemini 2.5Pro,不保證正確。
Last updated: 2025/7/18
Part 1:Google 搜尋的三個階段
1–1 第一階段:爬取 (Crawling) — 發現與收集資訊
階段任務: 發現網路上有哪些公開的網頁,並將它們的內容取回。
執行者: Googlebot (也稱為網路爬蟲、蜘蛛)。
運作方式:
- Googlebot 從一個已知的網址清單(例如過去爬過的網頁、網站管理員提交的 Sitemap)開始。
- 它會訪問這些網頁,並像使用者瀏覽網頁一樣,點擊頁面上的所有超連結 (Hyperlinks)。
- 透過這些連結,它會發現新的、從未見過的網頁,並將這些新網址加入到「待辦清單 (Crawl Queue)」中。
- 這個過程會永無止境地進行,不斷地在網路上爬行,尋找新的或更新過的內容。
1–2 第二階段:索引 (Indexing) — 理解與整理資訊
這是將雜亂資訊變為可用知識的關鍵步驟。
階段任務: 分析從「爬取」階段收集來的網頁內容,並將其整理、歸檔到一個巨大的資料庫中。
執行者: Google 的索引系統 (Caffeine)。
運作方式:
- Google 會「渲染 (Render)」爬取回來的頁面,執行頁面上的 JavaScript,以確保能看到和真人使用者幾乎一樣的內容。
- 接著,它會分析頁面的各種元素來理解頁面主題:
- 文字內容: 頁面上的標題、段落、關鍵字。
- 網頁結構: <h1>, <h2> 等標題標籤、alt 圖片替代文字。
- 媒體檔案: 分析圖片、影片等內容。
- 元數據 (Metadata): title 標籤、meta description 描述 - 分析完成後,Google 會將這些結構化的資訊存入一個稱為「索引 (Index)」的龐大資料庫中。
- 決定標準網址 (Canonicalization): 在索引一個頁面之前,Google 會判斷這個頁面是否存在多個版本(例如
http://vshttps://,wwwvs 非www,或內容高度相似的頁面)。Google 會從中選擇一個**「標準版本 (Canonical URL)」**來建立索引,並將其他版本的信號(如連結權重)整合到這個標準版本上。這能有效避免重複內容的問題。
1–3 第三階段:提供與排名 (Serving & Ranking) — 呈現最佳答案
這是使用者唯一能直接感受到的階段。
階段任務: 當使用者輸入查詢時,從「索引」中找出最相關、最權威的答案,並以最有用的方式呈現出來。
執行者: Google 的排名演算法。
運作方式:
- 理解查詢意圖: 當您輸入「台北 天氣」,Google 會理解您想知道的是即時的天氣預報,而不是關於天氣的科學論文。
- 匹配索引: Google 會在瞬間從它巨大的索引資料庫中,撈出所有與查詢相關的頁面。
- 進行排名 (Ranking): 這是最複雜的部分。Google 會使用數百個排名信號(演算法)來評估這些頁面的品質與相關性,決定它們的排序。常見的信號包括:
- 相關性: 頁面內容與查詢的匹配程度。
- 權威性: 網站的信譽、有多少其他高品質網站連結到它 (Backlinks)。
- 品質: 內容的原創性、深度、可信度。
- 使用者體驗: 網站速度 (Core Web Vitals)、行動裝置友善性、安全性 (HTTPS)。
- 使用者脈絡: 使用者的地理位置、搜尋歷史、語言等。
4. 呈現結果: 最後,Google 會將排好序的結果,以搜尋結果頁 (SERP) 的形式呈現給使用者。
Part 2:網站設定技巧
網站內容很重要,但不在此討論。
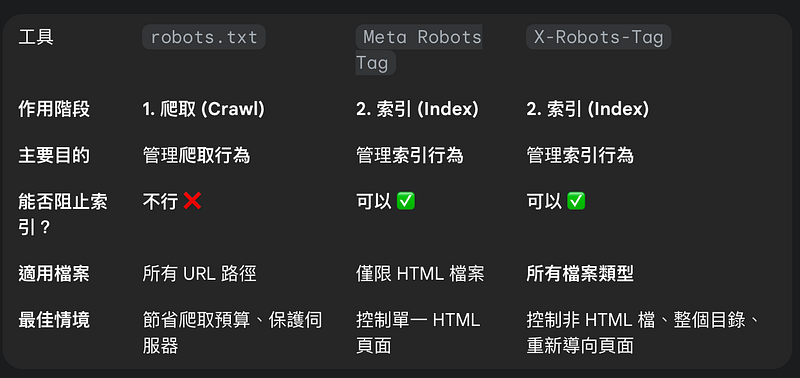
2–1 設定 robots.txt
當 Googlebot 決定要訪問一個網站 (網域) or子網域時 (例如 https://example.com),它做的第一件事,就是去檢查 https://example.com/robots.txt 這個檔案是否存在以及內容是什麼。
非必要但建議擁有。
假如沒有,Googlebot 尋找 https://example.com/robots.txt 時會收到404 (Not Found) 錯誤,Googlebot 的預設行為是「假設所有內容都允許被爬取」。
Allow & Disallow:如果您的 robots.txt 寫著 Disallow: /admin/,Googlebot 在看到這條規則後,就會跳過所有 https://example.com/admin/ 開頭的網址。
實際應用:主動告知 Sitemap 位置讓重要頁面更容易被爬取。把不想被爬取,例如:後台、購物車、內部搜尋結果等頁面,設定為 Disallow,可節省爬取預算 (Crawl Budget)、且避免被爬取需大量耗能的頁面。
幽靈索引:在example.com/admin/ 設定 disallow後,example.com/admin/ 仍可能被其他網站「Referral」,此時這個網頁還是會被 Googlebot 發現並索引、出現在搜尋結果中,但內容為空 -> 因為Googlebot 沒有讀取過網頁內容。
對比 noindex:robots.txt 用於管理爬取,noindex 指令用於管理索引。
2–2 設定 Meta Robots Tag
一段寫在特定網頁 HTML 原始碼 <head> 區段內的 <meta> 標籤。
運作原理:Googlebot 必須先下載整個網頁的 HTML 內容,然後在讀取分析 <head> 部分時,才會看到這條指令。
預設值:index, follow。通常可省略。
常用指令 (content=”…” 的內容):
noindex: 請勿將此頁面放入索引中(不要出現在搜尋結果裡)。follow: 告訴 Google 這個頁面上的連結(例如『返回首頁』),可以正常追蹤,權重也可以傳遞過去。nofollow: 請勿追蹤此頁面上的任何連結。noarchive: 請勿在搜尋結果中顯示此頁面的「快照」版本。nosnippet: 請勿在搜尋結果中顯示此頁面的文字摘要或影片預覽。- 組合使用,例如
content="noindex, nofollow"。 - 範例:<meta name=”robots” content=”noindex, follow”>
技術門檻:前端工程師或內容編輯者即可操作
2–3 設定 X-Robots-Tag
它不是寫在 HTML 裡,而是作為伺服器回應瀏覽器或爬蟲請求時的 HTTP 標頭 (HTTP Header) 的一部分。
運作原理: 在伺服器傳送任何 HTML 內容之前,就會先傳送包含 X-Robots-Tag 的 HTTP 標頭。Googlebot 在收到回應的瞬間,就能立刻知道該如何處理這個 URL。
技術門檻:通常需要後端或系統管理員協助
應用情境
- 阻止PDF / 圖片檔案被索引:因為 PDF 不是 HTML,您無法在裡面加入 Meta 標籤。實作方法 (以 Apache 伺服器的
.htaccess檔案為例): 在.htaccess設定檔中加入以下規則:
<Files "internal-guide.pdf">
Header set X-Robots-Tag "noindex"
</Files>- 阻止大規模、批次管理整個目錄的內容被索引,例如有一個
/previews/目錄,存放所有未完成的文章預覽。實作方法 (以.htaccess檔案為例):
<IfModule mod_headers.c>
<LocationMatch "/previews/">
Header set X-Robots-Tag "noindex, nofollow"
</LocationMatch>
</IfModule>- 阻止「重新導向 (Redirect)」的原始頁面被索引,例如網址 A (例如
/dashboard) 重新導向到網址 B (/login) 時,因為爬蟲無法讀到網址 A 的 HTML = 讀不到 Meta Robots Tag,所以只能用X-Robots-Tag標記網址A不要索引。
2–4 設定標準網址 (Canonical URL)
舉例:https://example.com/?utm_campagin=test&id=123&term=abc,標準網址為只包含必要參數(假設是id) 的網址https://example.com/?id=123 。
如何告訴 Google 哪個是標準網址?
- 使用
rel="canonical"連結標籤:最佳解。在所有重複版本的頁面的<head>中,加入指向標準版本的連結標籤,例如:<link rel="canonical" href="https://example.com/?id=123" />` - 在 Sitemap 中指定:只包含您希望被索引的標準網址。強度較弱。
其他情況:
- 非 HTML 檔案(如 PDF):使用 HTTP 標頭。因為無法使用 Meta 標籤。這時可以在伺服器回應標頭中加入
rel="canonical"指令,例如:Link: <https://example.com/canonical-version.pdf>; rel="canonical" - 確定某個舊網址要永久廢棄時:使用 301 重新導向 (301 Redirect)。當希望使用者和搜尋引擎都自動前往新網址時使用。例如,將所有 HTTP 流量永久導向到 HTTPS。
Part 3 :延伸
robots.txt的規則沒有任何強制力。阻擋惡意爬蟲和異常訪問應使用 身分驗證與授權 (Authentication & Authorization)、防火牆 (Firewall) / 網站應用程式防火牆 (WAF)、IP 封鎖與速率限制 (Rate Limiting)、CAPTCHA (驗證碼)- 索引與指令標籤 沒有標準化:主流搜尋引擎爬蟲會遵守,AI 爬蟲正在學習遵守與建立更專門的規則,舉例:no-ai-summary、cite-required。
- 結構化資料 (Structured Data)主流的格式有三種:
- JSON-LD:最常使用。放在網頁<head>,例如
<script type=”application/ld+json”>
{ “telephone”: “(02) 2721–7890”} - Microdata : 放在 <body> 的 html標籤中,例如
<p>電話:<span itemprop=”telephone”>(02) 2721–7890</span></p> - RDFa (Resource Description Framework in Attributes):放在 <body> 的 html標籤中。較少使用、也較複雜。
透過這些連結,它會發現新的、從未見過的網頁,並將這些新網址加入到「待辦清單 (Crawl Queue)」中。
這個過程會永無止境地進行,不斷地在網路上爬行,尋找新的或更新過的內容。
![[心得] 因為找不到完美的記帳工具,我讓 AI 幫我寫了一個:TallyLite 開發心得](/content/images/size/w600/2026/02/Gemini_Generated_Image_kv7r1bkv7r1bkv7r.png)
![[產品] TallyLite:我的個人記帳App](/content/images/size/w600/2026/02/TallyLite-Banner.png)